nginx事件循环及http请求处理流程分析
本篇blog是nginx源码分析系列的第一篇(也有可能是最后一篇,作者想到哪写到哪,太忙就不写了)。主要分析nginx事件循环以及http请求处理前半部分的代码(只涉及到nginx框架的处理部分)。
nginx的事件循环
众所周知nginx是一个事件驱动的web服务器,那么什么是事件驱动呢? 我个人理解,事件驱动可以用伪代码表示如下:
while(ture){
if(有事件可以处理) {
处理事件;
}
}
简单的说,事件驱动就是发现有事情可以做了就处理它,一直不断的循环下去,nginx的核心部分也就是一个事件处理的死循环。nginx一般以master-woker的多进程模式启动,在调试的时候也可以用单进程模式启动。但是不管是单进程模式还是多进程模式,他们的核心部分都是下面这一段函数:
for ( ;; ) {
//进入事件处理流程
ngx_process_events_and_timers(cycle);
//如果收到退出信号,退出死循环,做些其他处理
...
...
}
可以看出其实nginx 就是在死循环中不断的调用 ngx_process_events_and_timers 这个函数。nginx的事件处理也都在这个函数中完成。下面我们详细讲解一下这个函数的细节部分。
nginx中的事件
总的来说,在nginx的世界里有两类事件:
(1)网络IO事件
(2)定时器事件
网络IO事件由各操作系统提供的IO复用函数管理,在linux系统上就是我们非常熟悉的epoll,select 函数,一旦有新的网络IO事件产生,epoll等函数就会通知nginx来进行处理(读或者写)。定时器事件由nginx自己实现的红黑树进行管理,一旦有超时事件nginx就会执行相应的回调函数(openresty中的ngx.timer.at就是把事件注册到红黑树中)。
ngx_process_events_and_timers 函数详解
下面我们来详细看一下 ngx_process_events_and_timers 函数里面做了哪些事情
//就是获取一个sleep的定时时间
//设置了ngx_timer_resolution选项就是定时中断
if (ngx_timer_resolution) {
timer = NGX_TIMER_INFINITE;
flags = 0;
} else {
//从红黑树的定时器里面拿最小时间
timer = ngx_event_find_timer();
flags = NGX_UPDATE_TIME;
...
...
}
//解决惊群和负载均衡的accept锁
if (ngx_use_accept_mutex) {
if (ngx_accept_disabled > 0) {
ngx_accept_disabled--;
} else {
//尝试着去抢锁,抢到锁之后把监听端口的读事件加入epoll
if (ngx_trylock_accept_mutex(cycle) == NGX_ERROR) {
return;
}
if (ngx_accept_mutex_held) {
flags |= NGX_POST_EVENTS;
} else {
if (timer == NGX_TIMER_INFINITE
|| timer > ngx_accept_mutex_delay)
{
timer = ngx_accept_mutex_delay;
}
}
}
}
delta = ngx_current_msec;
//处理event事件,这是个封装好的东西,主要调用epoll_wait
//使用epoll 调用的是ngx_epoll_process_events
(void) ngx_process_events(cycle, timer, flags);
//计算epoll等待事件触发过程花费的时间
delta = ngx_current_msec - delta;
//先处理accept事件
ngx_event_process_posted(cycle, &ngx_posted_accept_events);
if (ngx_accept_mutex_held) {
//把锁放开
ngx_shmtx_unlock(&ngx_accept_mutex);
}
if (delta) {
//处理红黑树中的超时事件
ngx_event_expire_timers();
}
//放开锁后再去处理posted队列中的事件
ngx_event_process_posted(cycle, &ngx_posted_events);
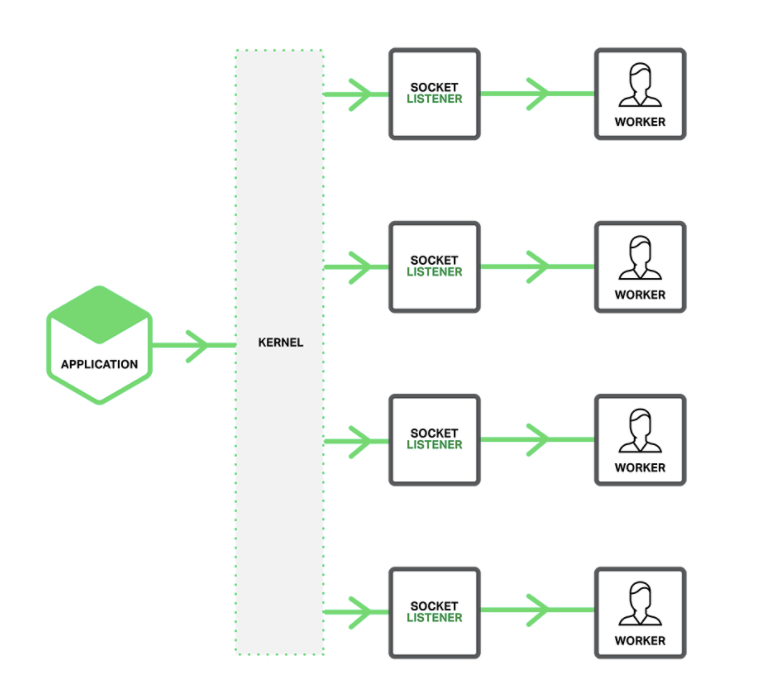
为了便于理解,我们先看看没有accept_mutex锁的情况是怎么回事(从1.11.3版本开始,为了提高性能accept_mutex锁不打开)。如果没有accept_mutex锁,整体处理流程如下所示:
(1)从红黑树或者设定好的固定值中获取一个超时时间
(2)调用epoll_wait等IO复用接口等待IO事件的到来
(3)处理posted_accept队列中的事件(两个队列的问题下面再介绍)
(4)处理红黑树中的超时事件
(5)处理posted队列中的事件。
可以看到其实基本逻辑就是:拿到一个超时时间 → 调用epoll_wait等待网络事件 → 处理准备好的事件。其中 posted_accept 队列和 posted 队列中的事件都是网络IO事件,红黑树中的事件都是调用nginx提供的接口函数注册进去的定时器事件。如果没有开启accept锁实际上posted_accept和posted队列会一直是个空队列,所有的网络事件都在 ngx_process_events 中处理了。
accept_mutex锁
为什么需要accept_mutex锁。一般来说有两个作用:
(1)解决操作系统的惊群问题(当然现在的Linux从内核层面已经解决这个问题了)
(2)对多个worker进程做负载均衡
接下来看一下抢锁的 ngx_trylock_accept_mutex 函数具体做了什么:
//获取到锁返回1,没有返回0
if (ngx_shmtx_trylock(&ngx_accept_mutex)) {
...
...
//抢到锁之后将监听连接的读事件加入epoll
if (ngx_enable_accept_events(cycle) == NGX_ERROR) {
ngx_shmtx_unlock(&ngx_accept_mutex);
return NGX_ERROR;
}
ngx_accept_events = 0;
ngx_accept_mutex_held = 1;
return NGX_OK;
}
....
....
if (ngx_accept_mutex_held) {
if (ngx_disable_accept_events(cycle, 0) == NGX_ERROR) {
return NGX_ERROR;
}
ngx_accept_mutex_held = 0;
}
主要是逻辑就是调用ngx_shmtx_trylock 函数去抢一把进程间的锁,只有抢到锁的进程才能讲监听fd上的读事件加到epoll中,没有抢到锁的进程需要把监听fd上的读事件从epoll中去除。总而言之只有抢到锁的进程才能接收新的网络请求,没有抢到锁的进程不能接收新的网络请求。nginx就是靠这把全局的锁来保证同一时刻只有一个进程能处理新的连接事件来避免惊群问题(没有抢到锁的进程就只能处理普通的网络读写事件和定时器事件)。由于篇幅所限,就不展开讲全局锁是怎么实现的了,大致思路就是如果系统支持原子变量就用共享内存中的原子变量来实现,不支持原子变量就用文件锁来实现(fcntl函数)。
那么负载均衡是怎么实现的呢?靠的是 ngx_accept_disabled 变量。我们注意到 ngx_process_events_and_timers 函数中有这么一段逻辑:
if (ngx_accept_disabled > 0) {
ngx_accept_disabled--;
} else {
....
....
}
即只有 ngx_accept_disabled 这个变量大于0的时候才有资格参与抢锁,ngx_accept_disabled 小于0的时候不会接受新的连接。每次nginx 处理新的连接的时候都会刷新一下 ngx_accept_disabled 的值,处理逻辑如下:
ngx_accept_disabled = ngx_cycle->connection_n / 8 - ngx_cycle->free_connection_n
ngx_accept_disabled = 总连接数 / 8 - 空闲连接数
也就是说当使用的连接数达到总连接数的 7/8 之后,当前进程就不会再接收新的连接了。(nginx使用的是连接池,启动的时候就把所有连接初始化好了,在高并发的情况下fd数不会无限增长,内存消耗也相对可控)。等待 ngx_accept_disabled 小于等于0之后(每次抢锁都会减一)才会重新开始接受新的连接。
虽然accept_mutex 有这么多作用,但是也有缺点,抢锁会导致nginx性能下降。事实上如果我们如果使用的是比较新的内核版本(linux 3.9)和nginx版本(1.9.x)那么这个accept_mutex就完全不需要了。理由如下:
(1)惊群的问题早已经被linux 内核解决,不再是一个问题。
(2)负载均衡的问题,在linux 3.9之后的内核,操作系统给socket提供了reuseport 这一选项。内核为每个Worker进程都建立了独立的ACCEPT队列,由内核将建立好的连接按负载分发到各队列中,不需要在软件层面再做负载均衡。只需要在listen指令后添加reuseport选项即可开启该功能。
那么accept_mutex的功能早已被内核取代,开启它会导致nginx性能下降,那么为什么不把它从代码中去掉呢?我说一下我自己的理解:nginx是一个跨平台的软件,不仅仅只有linux的用户在使用它,使用它的用户也不可能都是使用的比较新的Linux版本。作为一个跨平台的软件,nginx不能将自己的某些能力绑定依赖具体的操作系统实现,需要从软件层面来屏蔽这种差异(这也是为什么nginx中内存池,各种数据结构都是自己造轮子的原因之一)。
posted_accept 和 posted 队列
之前提到只有抢到accept_mutex的进程才允许接受新的网络连接,等锁放开之后其它的进程才能重新开始参与抢锁。也就是说这个锁一直不放开其它没有抢到锁的进程就没办法处理新的连接,那么这个锁应该锁多久呢?等抢到锁的进程把所有准备好的事件处理完毕显然是不合适的(锁的时间太长了)。nginx使用了posted_accept 队列和posted 队列来解决这个问题。posted_accept 队列里面是新的连接事件(就是有新的请求过来了,其实就是一次读事件),posted队列中是其它的网络IO事件(读写事件)。nginx在把posted_accept 队列里面的事件处理完毕之后就会把锁给放开,接着才会处理定时器中的超时事件和posted队列中的事件。这样就解决了占锁时间过长的问题。下面来看一下代码里面是怎么做的。从上文中的代码中我们可以看到nginx在抢锁之后会调用 ngx_process_events 函数,这是个函数指针(对于epoll它指向ngx_epoll_process_events)就是对IO复用wait接口的一些封装,使用不同的IO复用模型封装的接口也不一样,我们以epoll为例看看它是怎么做的:
rev->ready = 1;
//有post flag就根据这个accept判断加入哪个队列
//读事件有可能是新链接过来的情况
if (flags & NGX_POST_EVENTS) {
// accept是监听状态标志位,只有listening相关的事此标志位才为1
queue = rev->accept ? &ngx_posted_accept_events : &ngx_posted_events;
ngx_post_event(rev, queue);
} else {
//没有post flag就立即调用事件回调函数
rev->handler(rev);
}
....
....
//写事件一定是加入posted队列
//有post flag就加入posted队列
if (flags & NGX_POST_EVENTS) {
ngx_post_event(wev, &ngx_posted_events);
} else {
//没有就立即执行
wev->handler(wev);
}
从代码中可以看出,如果读事件是listen相关的事件(就是有新的连接过来了),那么就把该事件放到posted_accept队列,其它的读事件(已经建立好的链接有数据可以读了)放到posted队列。如果是写事件肯定是放到posted队列。如果没有accept_mutex那么就不用管这两个队列了(这两个队列肯定是空的)有事件过来执行就好了。
nginx中的模块
在讲nginx http请求处理流程之前我们有必要线简单介绍一下nginx中模块相应的知识。 nginx代码其实是由很多模块组成的,nginx只负责实现最核心的部分(配置解析功能,日志功能,网络操作的封装,基础的数据结构,内存池),定好一些接口,其它的部分其实都是由模块实现的。比如常见的事件处理,http请求处理,反向代理其实都是由各种模块实现的。这种代码组织方式能充分解耦,使代码可扩展,也正是由于这种模块化的架构,才催生了如此多的nginx第三方模块。nginx模块相关的知识很多很复杂,这里我们只是简单的介绍一下。
模块分类
nginx 官方模块可以分为5大类:核心模块,http模块,mail模块,事件模块,配置模块(现在应该还有个stream模块)。他们之间的关系如下图所示:
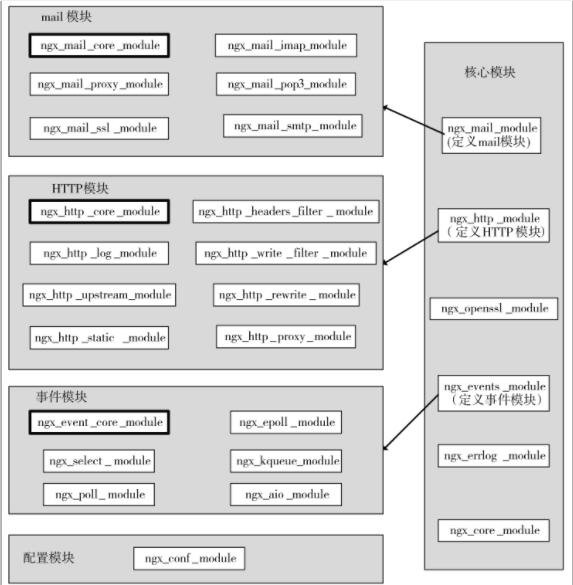
简单的来说核心模块只负责定义相应的模块(就是解析配置文件中的关键字比如http,event等等),而具体到每类模块的加载和管理都是由ngx_xxx_core_module模块做的。
http模块的种类 http模块大致可以分为以下3类:
(1)handlers 模块, 处理http请求并构造输出,比如常见的flv模块,限速模块都属于这一类
(2)filters 模块,处理handler产生的输出,名字中带filter的比如gzip模块属于这一类。
(3)upstream 模块,用作反向代理,http_proxy,memcached模块属于这一类。
其中handlers 模块都是挂载到http请求的某个阶段起作用(nginx的对http请求的某个处理有11个阶段)。filters 模块在handlers 模块向客户端输出响应时(通过ngx_http_output_filter函数)起作用。upstream模块其实也属于handler模块的一种,只不过它需要配合nginx 框架提供的一些函数来完成反向代理的功能,所以被单独列出来,但是大致开发使用流程和handlers 模块是一样的。
HTTP请求处理流程
概括的来说http请求大概会经过3个流程:
(1)解析request line
(2)解析header
(3)开始进入11个阶段,在各个阶段中被相应的http模块处理,如果有的模块有需要会读取body。
我们从一个新的http请求的tcp连接建立开始来逐步分析nginx代码处理流程。在nginx的配置文件中出现http块的时候,核心模块ngx_http_module定义的ngx_http_block函数会被调用,解析http块中的配置信息,做一些初始化工作。在本文中我们关注的部分代码如下:
...
...
if (ngx_http_init_phases(cf, cmcf) != NGX_OK) {
return NGX_CONF_ERROR;
}
...
...
// 执行每个http模块的postconfiguration函数指针
// 通常是向phase数组里添加handler
for (m = 0; cf->cycle->modules[m]; m++) {
if (cf->cycle->modules[m]->type != NGX_HTTP_MODULE) {
continue;
}
module = cf->cycle->modules[m]->ctx;
if (module->postconfiguration) {
if (module->postconfiguration(cf) != NGX_OK) {
return NGX_CONF_ERROR;
}
}
}
...
...
// 调用ngx_create_listening添加到cycle的监听端口数组,只是添加,没有其他动作
// 设置有连接发生时的回调函数ngx_http_init_connection
if (ngx_http_optimize_servers(cf, cmcf, cmcf->ports) != NGX_OK) {
return NGX_CONF_ERROR;
}
先暂时忽略http 处理阶段初始化的代码(这些代码完成了http phase 初始化以及各个handlers 模块挂载到相应处理阶段的功能 ),来看看ngx_http_optimize_servers函数做了什么。它主要做的工作就是经过一系列函数调用将http模块监听端口的相应的回调函数设置成ngx_http_init_connection。当http模块监听的端口有读事件发生时(就是有新的请求过来),ngx_http_init_connection 函数会被调用处理新建立的tcp连接。至于为什么有新的连接过来时,ngx_http_init_connection 函数会被调用,这个是事件模块做的事情,这里不做展开(就是对读事件设置了一堆回调函数)。ngx_http_init_connection函数对于该tcp连接的读写事件分别设置了两个回调函数:
// 处理读事件,读取请求头
// 设置了读事件的handler,可读时就会调用ngx_http_wait_request_handler
rev->handler = ngx_http_wait_request_handler;
// 暂时不处理写事件
c->write->handler = ngx_http_empty_handler;
一旦该tcp连接上面有数据可读,那么ngx_http_wait_request_handler函数会被被调用,由于此时还处于读client发送过来的信息的阶段不会有写事件可以处理,因此写事件的回调函数是个空函数(直接return)。在ngx_http_wait_request_handler函数中主要就是初始化ngx_http_request_t 数据结构用来储存http请求的一些数据(比如解析出来的header),然后开始解析request line。
//创建http_request结构体,放到data中去
c->data = ngx_http_create_request(c);
if (c->data == NULL) {
ngx_http_close_connection(c);
return;
}
//开始解析request_line
//走到这里数据可能还没有读完,后面的函数会继续读
rev->handler = ngx_http_process_request_line;
//解析request_line
ngx_http_process_request_line(rev);
由于代码过于复杂,在这里不详细展开nginx是如何解析request line的。基本思路就是用一个状态机(有26个状态),不停的从socket中读取数据,然后解析request line中的信息(method,uri 等等)放到之前初始化好的http结构体中。
enum {
sw_start = 0,
sw_method,
sw_spaces_before_uri,
sw_schema,
sw_schema_slash,
sw_schema_slash_slash,
sw_host_start,
sw_host,
sw_host_end,
sw_host_ip_literal,
sw_port,
sw_host_http_09,
sw_after_slash_in_uri,
sw_check_uri,
sw_check_uri_http_09,
sw_uri,
sw_http_09,
sw_http_H,
sw_http_HT,
sw_http_HTT,
sw_http_HTTP,
sw_first_major_digit,
sw_major_digit,
sw_first_minor_digit,
sw_minor_digit,
sw_spaces_after_digit,
sw_almost_done
} state;
为什么需要用到状态机呢?因为nginx中的socket都是非阻塞的,不可能一下子就把所有client发送过来的数据读完(如果是阻塞io会一直阻塞到把所有数据读完),等把缓冲区的数据读取完毕之后,socket会返回一个EAGAIN错误代表没有数据可读了。此时就需要把当前解析到的状态记录下来返回,把线程让出来让nginx处理其它的事件。等socket下次又有数据可读的时候,会有新的读事件产生,此时就可以从上次没有解析完的地方继续解析。
等待request line解析完之后就可以开始解析header了
c->log->action = "reading client request headers";
//uri读完了,开始读header
//设置handler
rev->handler = ngx_http_process_request_headers;
ngx_http_process_request_headers(rev);
return;
同样的,在解析header的时候也是使用状态机(8个状态),不停的从socket中读取数据然后解析。等到header解析完之后,http请求的解析就会暂停,不会再读接下来的body部分(肯定不可能恰好读到header结束的部分就停止了,此时读到的数据肯定是有一部分是属于body的数据)。这样处理是为了性能考虑,因为一般来说body比较大读取比较耗时,保存起来也比较耗内存,并且有些http请求处理我们并不需要body,因此nginx一开始是不会读body的,等到有些http模块需要用到body的时候再调用ngx_http_read_client_request_body函数读取(就算重复调用也是可以的,有缓存),如果不需要用到body会调用ngx_http_discard_request_body读body,但是不会分配内存保存,会直接把内容丢掉。等到header也解析完成之后就开始使用http模块正式处理http请求。
//header全部解析完
if (rc == NGX_HTTP_PARSE_HEADER_DONE) {
/* a whole header has been parsed successfully */
ngx_log_debug0(NGX_LOG_DEBUG_HTTP, r->connection->log, 0,
"http header done");
r->request_length += r->header_in->pos - r->header_name_start;
r->http_state = NGX_HTTP_PROCESS_REQUEST_STATE;
//检查一下有些header是否合法
rc = ngx_http_process_request_header(r);
if (rc != NGX_OK) {
return;
}
//开始使用http模块正式处理http请求
ngx_http_process_request(r);
return;
}
我们来看一看ngx_http_process_request 函数做了什么
//重新设置读写事件
//ngx_http_process_request方法负责在接收完HTTP头部后,第一次与各个HTTP模块共同按阶段处理请求
//如果ngx_http_process_request没能处理完请求,这个请求上的事件再次被触发,那就将由此方法继续处理了。
c->read->handler = ngx_http_request_handler;
c->write->handler = ngx_http_request_handler;
/*
设置ngx_http_request_t结构体的read_event_handler方法ngx_http_block_reading。当再次有读事件到来时,将会调用ngx_http_block_reading方法
处理请求。而这里将它设置为ngx_http_block_reading方法,这个方法可认为不做任何事,它的意义在于,目前已经开始处理HTTP请求,除非某个HTTP模块重新
设置了read_event_handler方法,否则任何读事件都将得不到处理,也可似认为读事件被阻塞了。
*/
r->read_event_handler = ngx_http_block_reading;
//头解析完后开始调用各个http模块的handle
ngx_http_handler(r);
//处理子请求
ngx_http_run_posted_requests(c);
首先设置了tcp 连接的读写事件回调函数为ngx_http_request_handler,这个函数就是单纯的直接调用http结构体中的读写回调函数。也就是说进入到http请求处理阶段之后tcp连接上的读写函数就变成了http 请求结构体中的读写函数。从上面事件循环的介绍我们可以发现,nginx是不知道它执行的是什么事件,是http模块的事件呢还是stream模块的事件,它只知道这个是tcp连接上的事件。经过这样处理之后其实对于http模块来说nginx处理的IO事件就是http 请求结构体中设置的读写函数。这是一种代码抽象的技巧吧,进入到http模块的处理流程之后,tcp连接上的东西都被屏蔽了,我们看到的只有http相关的东西。
同时注意到会把http 请求的读函数(其实也是http请求对应tcp连接的读函数)设置为ngx_http_block_reading。这个函数会把读事件从epoll中删除,也就是说这个连接上的读事件被阻塞了,在重新设置回调函数之前不会进行读操作。
等这些都做完之后就开始(子请求处理部分本文不讲)调用各个http模块提供的handle 函数进行11个阶段的处理工作。ngx_http_handler函数在做完一些初始化工作之后就调用ngx_http_core_run_phases 来调用配置中用到的http模块在各阶段提供的回调函数。我们看一下代码是怎样的
// 得到core main配置
cmcf = ngx_http_get_module_main_conf(r, ngx_http_core_module);
// 获取引擎里的handler数组
ph = cmcf->phase_engine.handlers;
// 从phase_handler的位置开始调用模块处理
// 外部请求的引擎数组起始序号是0,从头执行引擎数组,即先从Post read开始
// 内部请求,即子请求.跳过post read,直接从server rewrite开始执行,即查找server
while (ph[r->phase_handler].checker) {
// 调用引擎数组里的checker
rc = ph[r->phase_handler].checker(r, &ph[r->phase_handler]);
// checker会检查handler的返回值
// 如果handler返回again/done那么就返回ok
// 退出引擎数组的处理
// 由于r->write_event_handler = ngx_http_core_run_phases
// 当再有写事件时会继续从之前的模块执行
//
// 如果checker返回again,那么继续在引擎数组里执行
// 模块由r->phase_handler指定,可能会有阶段的跳跃
if (rc == NGX_OK) {
return;
}
}
可以看出这个函数就是遍历http的各个处理阶段(不一定是按顺序的,下次执行哪个阶段由上一个阶段中的回调函数决定,会有阶段的跳跃),用nginx框架提供给每个阶段的check 方法来执行各个http模块注册好的回调函数。也就是说各个http模块提供的回调函数必须在nginx的check函数设置好的规则下来起作用。下面我们详细讲一下http请求阶段相关的知识。
HTTP 请求的11个阶段
http请求有哪11个阶段,每个阶段做哪些事情,网上资料有很多,这里就不展开讲了。我们先看一下对于 “阶段” 这个东西在nginx中是怎么定义的。
typedef struct ngx_http_phase_handler_s ngx_http_phase_handler_t;
typedef ngx_int_t (*ngx_http_phase_handler_pt)(ngx_http_request_t *r,
ngx_http_phase_handler_t *ph);
struct ngx_http_phase_handler_s {
//框架实现的checker方法
ngx_http_phase_handler_pt checker;
//http模块实现的handler方法
ngx_http_handler_pt handler;
//下一个阶段序号
ngx_uint_t next;
};
它主要由三个部分组成: (1)nginx框架实现的checker 方法 (2)http模块提供的handler方法 (3)下一个阶段序号。
在配置文件中的http块解析完成的时候,nginx会根据配置文件中各http模块的信息生成ngx_http_phase_handler_t 数组(就是在上面的ngx_http_init_phases函数中完成),最终phase数组的数据会保存在 ngx_http_phase_engine_t 结构体中(就是上面的cmcf变量)。ngx_http_phase_engine_t如下所示
typedef struct {
// 存储所有handler/checker的数组,里面用next实现阶段的快速跳转
ngx_http_phase_handler_t *handlers;
// server重写的跳转位置
ngx_uint_t server_rewrite_index;
// location重写的跳转位置
ngx_uint_t location_rewrite_index;
} ngx_http_phase_engine_t;
在http请求的header解析完之后,nginx会遍历 handlers 数组中的数据来执行http 模块注册在各个阶段中的回调函数。这个回调函数的执行是通过nginx提供给每个阶段的checker函数来执行(checker函数的第一个参数是http结构体,第二个参数是http模块注册的回调函数)。一个阶段只有一个checker方法,各个阶段的checker方法如下所示:
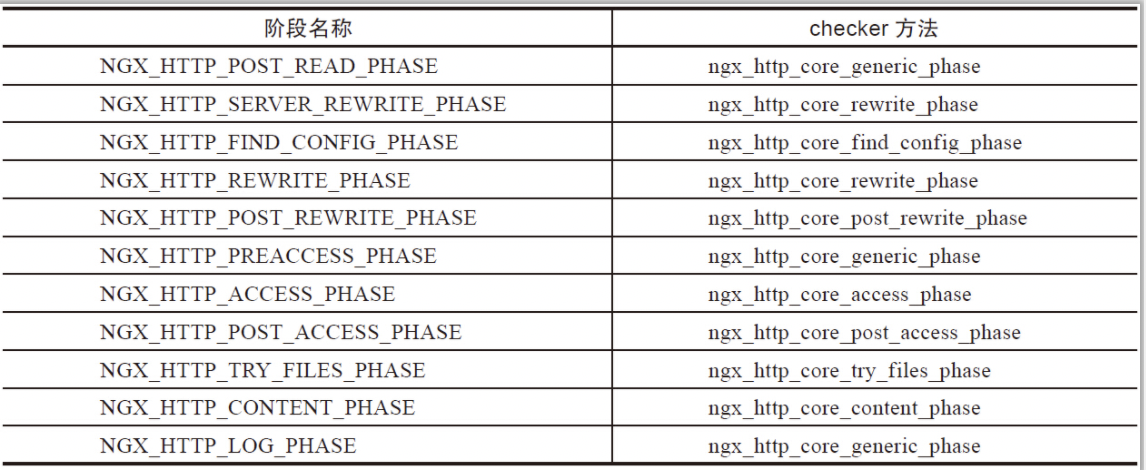
那么为什么需要checker 方法呢?因为在HTTP请求的不同阶段有不同的特点,nginx希望用这些checker方法对各个http模块提供的回调函数的执行做一些统一的约束。我个人总结下来大概有如下3种情况:
(1)请求顺序控制。比如,某个阶段可能会有多个http 模块介入,有些阶段允许在一个http模块的handler函数执行完毕之后跳过其它http模块的handler函数(根据handler返回值不同)直接进入下一个阶段,有些阶段不允许跳过只能一个个按顺序执行挂载到该阶段的handler函数。还有一些阶段只允许执行一个handler函数。这些都是靠不同的checker函数来约束的。
(2)某些阶段是不允许http 模块进行挂载的,只能由nginx来进行处理,这些阶段的checker函数就不会调用相应的handler函数。
(3)ngx_http_core_content_phase 比较特殊,NGX_HTTP_CONTENT_PHASE 也是第三方模块介入最多的阶段(构造http输出的阶段)。它既允许http 模块像其它阶段一样,通过将自己的handler函数插入phase 数组中,也允许它直接设置http结构体中的handler 方法。但是如果采用第二种方法那么在此阶段只有一个handler会起作用,并且nginx优先使用第二种方法。
下面我们以几个个比较典型的checker函数来具体看一看。首先看看用的最多的ngx_http_core_generic_phase
//执行当前阶段的handler方法
rc = ph->handler(r);
//返回ok执行下一个阶段
if (rc == NGX_OK) {
r->phase_handler = ph->next;
return NGX_AGAIN;
}
//执行下一个handler 因为一个阶段可能会有多个handler
if (rc == NGX_DECLINED) {
r->phase_handler++;
return NGX_AGAIN;
}
//返回这个直接返回,把控制权交给epoll下次继续执行这个方法
if (rc == NGX_AGAIN || rc == NGX_DONE) {
return NGX_OK;
}
/* rc == NGX_ERROR || rc == NGX_HTTP_... */
//错误之类的错误码结束请求
ngx_http_finalize_request(r, rc);
return NGX_OK;
可以看到根据handler返回值不一样它可以跳过该阶段的其它handler直接进入下一个阶段或者按顺序执行当前阶段的handler。
再看看ngx_http_core_rewrite_phase
ngx_int_t rc;
ngx_log_debug1(NGX_LOG_DEBUG_HTTP, r->connection->log, 0,
"rewrite phase: %ui", r->phase_handler);
rc = ph->handler(r);
if (rc == NGX_DECLINED) {
r->phase_handler++;
return NGX_AGAIN;
}
//不用到下一个handler会再次被调用
if (rc == NGX_DONE) {
return NGX_OK;
}
/* NGX_OK, NGX_AGAIN, NGX_ERROR, NGX_HTTP_... */
ngx_http_finalize_request(r, rc);
return NGX_OK;
可以看出这个checker对应的阶段不允许跳过handler函数只能一个一个handler执行。还有一些阶段不允许http 模块介入的(11个阶段我们只能介入8个阶段),那么该阶段的checker就不会调用传入的handler方法(比如ngx_http_core_find_config_phase),你传了也没用。
最后我们看看比较特殊的ngx_http_core_content_phase
// 检查请求是否有handler,也就是location里定义了handler
if (r->content_handler) {
// 设置写事件为ngx_http_request_empty_handler
// 即暂时不再进入ngx_http_core_run_phases
// 这是因为内容产生阶段已经是“最后”一个阶段了,不需要再走其他阶段
// 之后发送数据时会改为ngx_http_set_write_handler
// 但我们也可以修改,让写事件触发我们自己的回调
r->write_event_handler = ngx_http_request_empty_handler;
// 调用location专用的内容处理handler
// 返回值传递给ngx_http_finalize_request
// 相当于处理完后结束请求
// 这种用法简化了客户代码,相当于模板方法模式
// rc = handler(r); ngx_http_finalize_request(rc);
//
// 结束请求
// 但如果count>1,则不会真正结束
// handler可能返回done、again,例如调用read body
ngx_http_finalize_request(r, r->content_handler(r));
// 需要在之后的处理函数里继续处理,不能调用write_event_handler
return NGX_OK;
}
ngx_log_debug1(NGX_LOG_DEBUG_HTTP, r->connection->log, 0,
"content phase: %ui", r->phase_handler);
// 没有专门的handler
// 调用每个模块自己的处理函数
rc = ph->handler(r);
if (rc != NGX_DECLINED) {
ngx_http_finalize_request(r, rc);
return NGX_OK;
}
/* rc == NGX_DECLINED */
// 模块handler返回decline,表示不处理
ph++;
// 这里要检查引擎数组是否结束,最后一个元素是空的
if (ph->checker) {
// 继续在本阶段(rewrite)里查找下一个模块
// 索引加1
r->phase_handler++;
// again继续引擎数组的循环
return NGX_AGAIN;
}
可以看出他会优先使用ngx_http_moudle_t中的handler 方法,这个函数没有设置才会调用phase数组中的handler。并且会优先使用ngx_http_moudle_t中的handler 方法。
那么http 模块是如何介入相应阶段的呢(指的是handler 模块和 upstream模块,filter模块和这个不一样)? 这个问题其实早有了答案,他们在自己的 postconfiguration 函数中将自己的handler 方法添加到相应阶段的phase数组中就行了,从前面ngx_http_block 函数的代码中我们可以看到nginx在解析配置的时候调用每个http模块的postconfiguration 函数 ,此时各个http模块的handler方法就会被添加到phase数组中。如果你想要介入的阶段是content阶段,那么还可以通过设置ngx_http_moudle_t中的handler 方法的方式。
目前为止由nginx处理的http请求的流程就基本结束了,剩下的事情交给各种http模块来进行处理,他们可以按照自己的想法构造输出内容(handler模块来完成),对输出进行各种过滤(filter模块来完成),或者把http请求代理到上游其它服务那里去(upstream模块来完成)。